- 4.9/5.0
- 402 Questions
- Updated on: 8-Jul-2026
- Understanding Cisco Cybersecurity Operations Fundamentals (CBROPS)
- 24025 Prepared
Free Cisco 200-201 Practice Questions 2026 | Understanding Cisco Cybersecurity Operations Fundamentals (CBROPS)
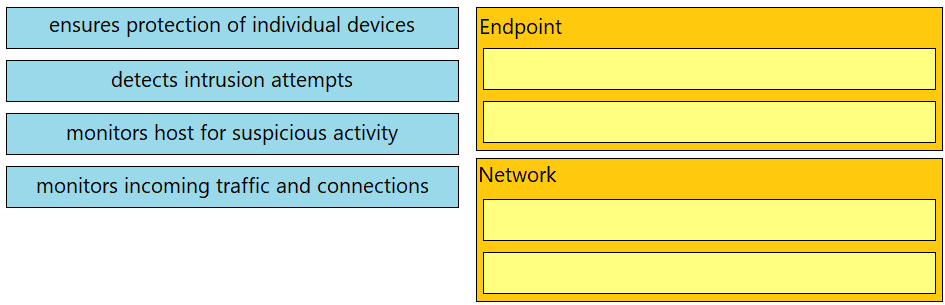
Drag and drop the uses on the left onto the type of security system on the right.
Refer to the exhibit.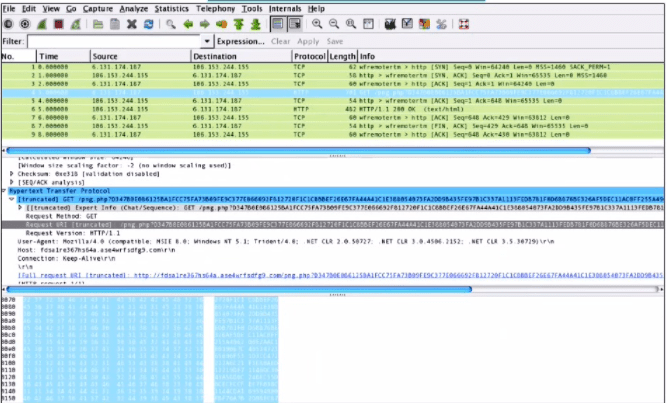
What is shown in this PCAP file?
A. Timestamps are indicated with error.
B. The protocol is TCP.
C. The User-Agent is Mozilla/5.0.
D. The HTTP GET is encoded
Explanation: The PCAP file shows a network packet capture of an HTTP GET request from a client to a server. The User-Agent header field identifies the type and version of the client software that generated the request. In this case, the User-Agent is Mozilla/5.0, which indicates that the client is using a Mozilla-based browser or application. The User- Agent can help the server to customize the response based on the client’s capabilities and preferences.
| Page 17 out of 41 Pages |